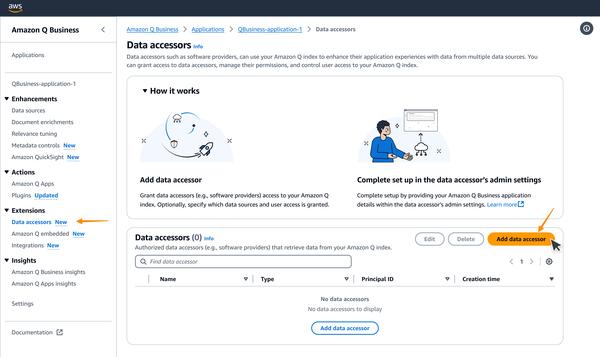
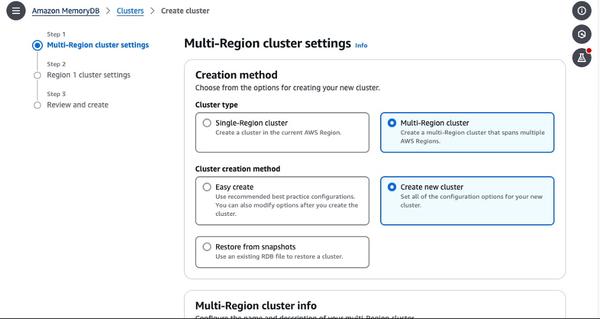
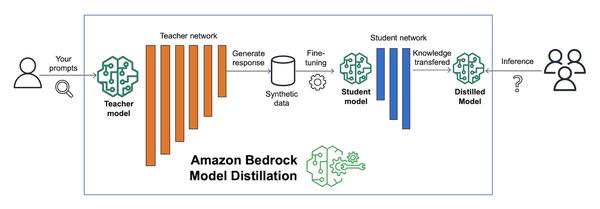
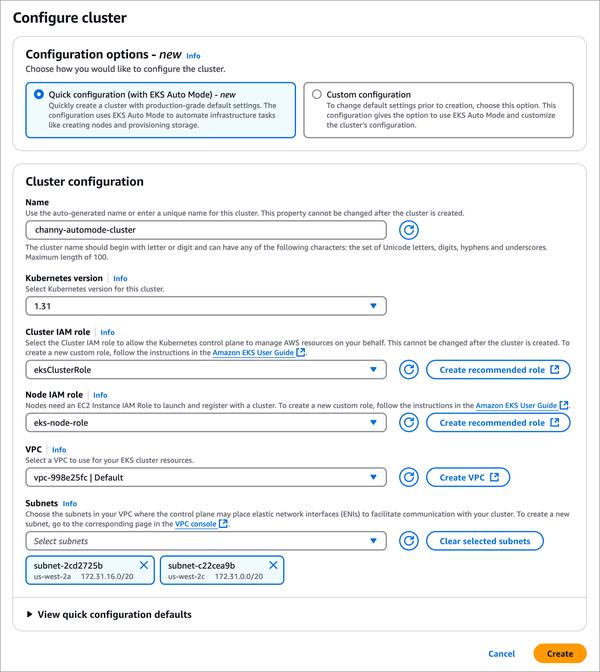
Google hat einen Blogbeitrag über die Feinabstimmung großer Sprachmodelle veröffentlicht, mit Schwerpunkt auf Gemma. Der Artikel bietet einen Überblick über den Prozess von Anfang bis Ende, von der Vorbereitung des Datensatzes bis zur Feinabstimmung eines anweisungsgesteuerten Modells.
Besonders interessant fand ich die Betonung der Wichtigkeit der Datenvorbereitung und der Hyperparameteroptimierung. Es ist klar, dass diese Aspekte einen großen Einfluss auf die Leistung des Modells haben können und sorgfältig berücksichtigt werden müssen.
Eine Herausforderung, die ich in meiner Arbeit häufig sehe, besteht darin, sicherzustellen, dass Chatbots Nuancen in der Sprache verstehen, komplexe Dialoge führen und genaue Antworten liefern. Der in diesem Blogbeitrag beschriebene Ansatz scheint eine vielversprechende Lösung für dieses Problem zu bieten.
Ich würde gerne mehr über die Details des Hyperparameter-Tuning-Prozesses erfahren. Zum Beispiel, welche spezifischen Parameter wurden angepasst und wie wurden die optimalen Werte ermittelt? Eine ausführlichere Diskussion dieses Aspekts wäre sehr hilfreich.
Insgesamt fand ich diesen Blogbeitrag sehr informativ und er bietet einen nützlichen Überblick über die Feinabstimmung großer Sprachmodelle. Ich denke, diese Informationen werden für jeden von großem Wert sein, der Chatbots oder andere sprachbasierte Anwendungen erstellen möchte.