Amazon Data Firehose führt eine neue Funktion ein, die Datenbankänderungen erfasst und Aktualisierungen an einen Data Lake oder ein Warehouse streamt und PostgreSQL, MySQL, Oracle, SQL Server und MongoDB mit automatischer Skalierung und minimalen Auswirkungen auf die Transaktionsleistung unterstützt. Diese neue Funktion bietet eine einfache End-to-End-Lösung zum Streamen von Datenbankaktualisierungen, ohne die Transaktionsleistung von Datenbankanwendungen zu beeinträchtigen. Sie können in wenigen Minuten einen Data Firehose-Stream einrichten, um CDC-Aktualisierungen (Change Data Capture) von Ihrer Datenbank bereitzustellen. Jetzt können Sie Daten aus verschiedenen Datenbanken einfach in Iceberg-Tabellen auf Amazon S3 replizieren und aktuelle Daten für umfangreiche Analysen und Machine-Learning-(ML)-Anwendungen verwenden. Typische AWS-Unternehmenskunden verwenden Hunderte von Datenbanken für Transaktionsanwendungen. Um umfangreiche Analysen und ML mit den neuesten Daten durchzuführen, möchten sie Änderungen erfassen, die in Datenbanken vorgenommen wurden, z. B. wenn Datensätze in einer Tabelle eingefügt, geändert oder gelöscht werden, und die Aktualisierungen an ihr Data Warehouse oder ihren Amazon S3 Data Lake in Open-Source-Tabellenformaten wie Apache Iceberg liefern. Zu diesem Zweck entwickeln viele Kunden ETL-Jobs (Extract, Transform, Load), um regelmäßig aus Datenbanken zu lesen. ETL-Reader beeinträchtigen jedoch die Transaktionsleistung der Datenbank, und Batch-Jobs können mehrere Stunden Verzögerung hinzufügen, bevor Daten für Analysen verfügbar sind. Um die Auswirkungen auf die Transaktionsleistung der Datenbank zu verringern, möchten Kunden die Möglichkeit haben, Änderungen zu streamen, die in der Datenbank vorgenommen wurden. Dieser Stream wird als Change Data Capture (CDC)-Stream bezeichnet. Mit dieser neuen Datenstreaming-Funktion fügt Amazon Data Firehose die Möglichkeit hinzu, CDC-Streams von Datenbanken zu erfassen und kontinuierlich auf Apache Iceberg-Tabellen auf Amazon S3 zu replizieren. Sie richten einen Data Firehose-Stream ein, indem Sie die Quelle und das Ziel angeben. Data Firehose erfasst und repliziert kontinuierlich einen anfänglichen Datensnapshot und dann alle nachfolgenden Änderungen an den ausgewählten Datenbanktabellen als Datenstrom. Um CDC-Streams zu erfassen, verwendet Data Firehose das Datenbankreplikationsprotokoll, wodurch die Auswirkungen auf die Transaktionsleistung der Datenbank reduziert werden. Wenn das Volumen der Datenbankaktualisierungen zu- oder abnimmt, partitioniert Data Firehose die Daten automatisch und speichert Datensätze, bis sie an das Ziel geliefert werden. Sie müssen keine Kapazität bereitstellen oder Cluster verwalten und optimieren. Zusätzlich zu den Daten selbst kann Data Firehose beim Erstellen des anfänglichen Data Firehose-Streams automatisch Apache Iceberg-Tabellen mit demselben Schema wie die Datenbanktabellen erstellen und das Zielschema automatisch weiterentwickeln, z. B. durch Hinzufügen neuer Spalten, basierend auf Änderungen des Quellschemas. Da Data Firehose ein vollständig verwalteter Dienst ist, müssen Sie sich nicht auf Open-Source-Komponenten verlassen, Software-Updates anwenden oder Betriebskosten tragen.
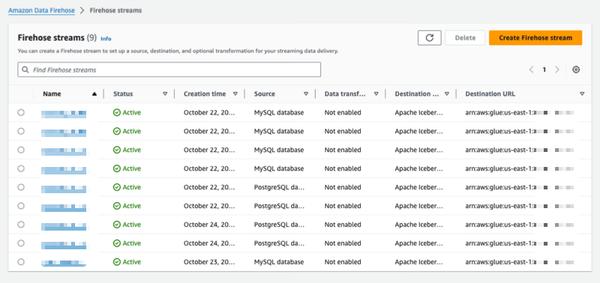
Replizieren Sie Änderungen von Datenbanken in Apache Iceberg-Tabellen mithilfe von Amazon Data Firehose (in der Vorschau)
AWS