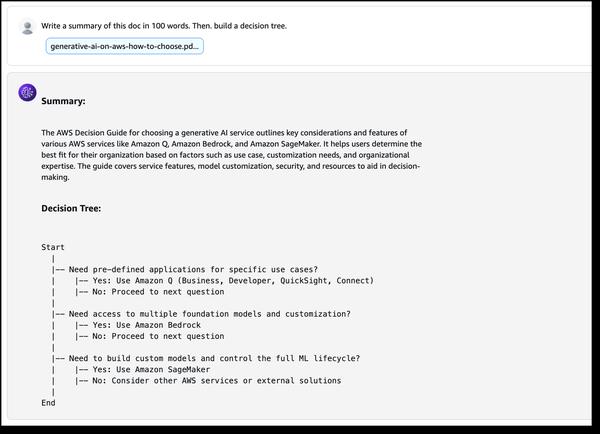
Amazon Bedrock hat neue Evaluierungsmöglichkeiten für RAG und LLM-as-a-Judge angekündigt, die das Testen und Verbessern generativer KI-Anwendungen vereinfachen. Amazon Bedrock Knowledge Bases unterstützt jetzt die RAG-Evaluierung, die es Ihnen ermöglicht, eine automatische Wissensdatenbank-Evaluierung durchzuführen, um RAG-Anwendungen zu bewerten und zu optimieren. Der Evaluierungsprozess verwendet ein großes Sprachmodell (LLM), um die Metriken für die Evaluierung zu berechnen. So können Sie verschiedene Konfigurationen vergleichen und Ihre Einstellungen optimieren, um die gewünschten Ergebnisse für Ihren Anwendungsfall zu erzielen. Die Amazon Bedrock-Modellevaluierung umfasst jetzt LLM-as-a-Judge, mit der Sie Tests durchführen und andere Modelle mit menschenähnlicher Qualität zu einem Bruchteil der Kosten und Zeit menschlicher Evaluierungen bewerten können. Diese neuen Funktionen erleichtern die Inbetriebnahme, indem sie eine schnelle, automatisierte Evaluierung von KI-gestützten Anwendungen ermöglichen, Feedbackschleifen verkürzen und Verbesserungen beschleunigen. Diese Evaluierungen bewerten mehrere Qualitätsdimensionen, darunter Korrektheit, Nützlichkeit und Kriterien für verantwortungsvolle KI wie Antwortverweigerung und Schädlichkeit. Um die Bedienung einfach und intuitiv zu gestalten, liefern die Evaluierungsergebnisse natürlichsprachliche Erklärungen für jede Punktzahl in der Ausgabe und auf der Konsole, und die Punktzahlen werden zur besseren Interpretierbarkeit von 0 bis 1 normalisiert. Die Rubriken werden vollständig mit den Judge-Prompts in der Dokumentation veröffentlicht, damit auch Nicht-Wissenschaftler verstehen können, wie die Punktzahlen abgeleitet werden.
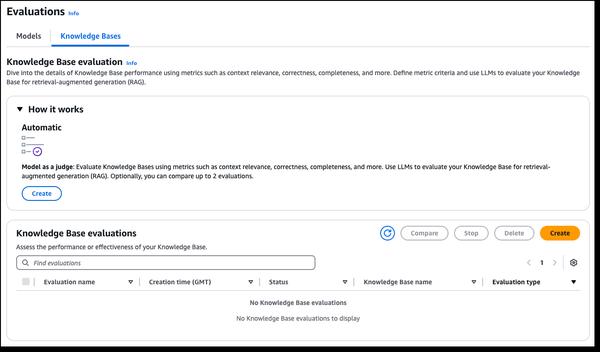
Neue RAG-Evaluierung und LLM-as-a-Judge-Funktionen in Amazon Bedrock
AWS